Redefining XPU Memory for AI Data Centers Through Custom HBM4 - Part 3
Part 3: implementing custom HBM
by Archana Cheruliyil
Principal Product Marketing Manager
This is the third and final of a series from Alphawave Semi on HBM4 and gives and examines custom HBM implementations. Click here for part 1, which gives an overview of the HBM standard, and here for part 2, on HBM implementation challenges.
This follows on from our second blog, where we discussed the substantial improvements high bandwidth memory (HBM) provides over traditional memory technologies for high-performance applications, and in particular AI training, deep learning, and scientific simulations. In this, we detailed the various advanced design techniques implemented during the pre-silicon design phase. We also highlighted the critical need for more innovative memory solutions to keep pace with the data revolution as AI has pushed the boundaries of what computational systems can do. A custom implementation of HBM allows for greater integration with compute dies and custom logic and can, therefore, be a performance differentiator justifying its complexity.
Custom High Bandwidth Memory systems
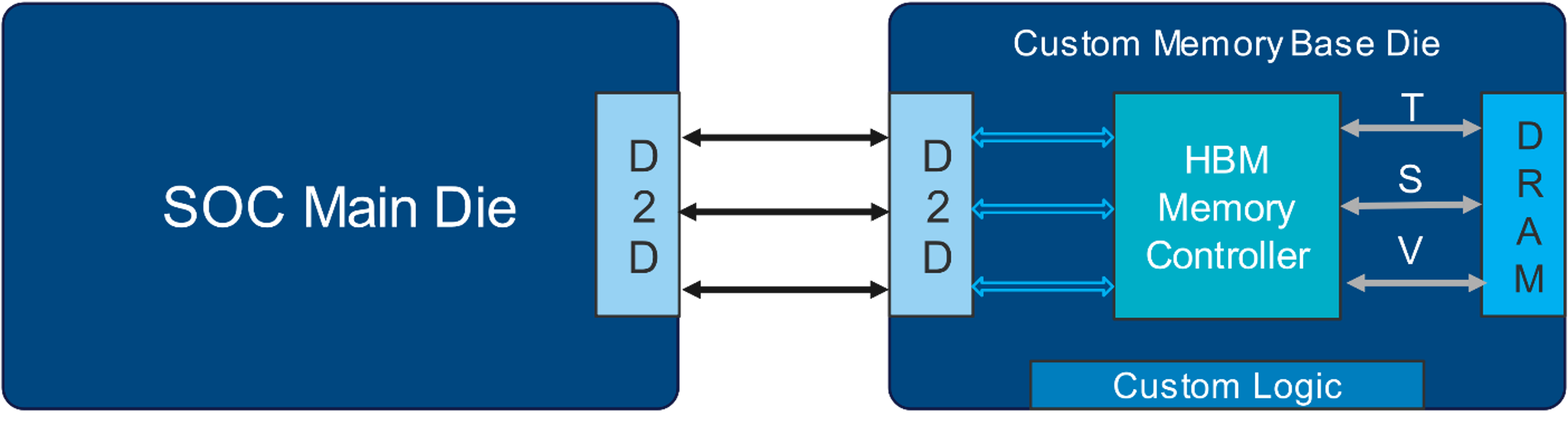
Creating custom HBM using a die-to-die interface such as the UCIe standard (Universal Chiplet Interconnect Express) is a cutting-edge approach that involves tightly integrating memory dies with compute dies to achieve extremely high bandwidth as well as a low latency between the components. In such an implementation, the memory controller directly interfaces with the HBM DRAM through a Through-Silicon-Via (TSV) PHY on the memory base die. Commands from the host or compute are translated through a die-to-die interface using a streaming protocol. This allows for reuse of die-to-die shoreline already occupied on the main die for core-to-core or core-to-I/O connections. Such an implementation requires a close collaboration between IP vendors, DRAM vendors and end customers to create a custom memory base die.
Alphawave Semi is uniquely positioned to pioneer this effort with cutting-edge HBM4 memory controller portfolio and recently announced, the industry’s first silicon proven 3 nm, 24 Gbps die-to-die UCIe IP subsystem delivering 1.6 TB/s of bandwidth. In addition to this, Alphawave can design and build the custom ASIC die in-house, with close collaboration with end customers.
Benefits of a Custom HBM Integration:
1. Better alignment of memory vs needs
A custom HBM4 design means optimizing the memory and memory controller to align closely with the specific needs of the processor or AI accelerator. This may involve tweaking the memory configuration (for example, by increasing bandwidth, reducing latency, or adding more memory layers) and fine-tuning the die-to-die interface to ensure smooth and fast communication. Alphawave Semi offers a highly configurable HBM4 memory controller that supports all JEDEC defined parameters and can be customized to meet specific workloads.
2. 2.5D integration
In 2.5D packaging, the processor die and HBM custom dies are placed side-by-side on an interposer, which acts as a high-speed communication bridge between them. This approach allows for wide data buses and short interconnects, resulting in higher bandwidth and lower latency. Alphawave Semi has deep expertise in designing 2.5D systems with interposer and package design. The resulting system-in-package is tested extensively for signal and power integrity.
3. The die-to-die interface gives improved bandwidth
Die-to-die interfaces can support very wide data buses at high clock rates, resulting in massive bandwidth throughput. For example, Alphawave Semi’s UCIe link on a single advanced package module running at 24 Gbps lanes can drive up to 1.6 Tbps per direction.
4. It also improves latency
By reducing the distance between the memory and processor, die-to-die interfaces minimize the latency that comes from accessing external memory. This is critical in AI model training and inference, where latency can significantly impact performance.
5. And power efficiency
The shorter interconnect distances and reduced need for external memory controllers lower power consumption. This is a key advantage for data centers running power-intensive AI workloads, as well as for edge AI devices where power efficiency is crucial.
High-bandwidth memory (HBM) was initially developed to enhance memory capacity in 2.5D packaging. Today, it has become essential for high-performance computing. In this interview for Semiconductor Engineering Magazine, Ed Sperlink speaks with Archana Cheruliyil, Principal Product Marketing Manager at Alphawave Semi, about the evolution of HBM and its impact on the industry.
Summary
When combined with a die-to-die interface, custom HBM provides a powerful solution that helps address the memory bottleneck problem faced by AI chips. By leveraging advanced packaging technologies like 2.5D and 3D stacking, AI chips can achieve ultra-high memory bandwidth, lower latency, and greater power efficiency. This is crucial for handling the massive data requirements of modern AI workloads, particularly in applications such as deep learning, real-time inference, and high-performance computing. While there are challenges in terms of cost and thermal management, the performance benefits make this approach highly valuable for next-generation AI hardware systems.
Alphawave Semi is uniquely positioned to provide complex, high-performance SoC implementations by utilizing our superior HBM4 solutions, our industry-leading portfolio of connectivity IP solutions to complement our HBM4, and the ability to bring it all together using our in-house custom silicon expertise
Check out our 3-part blog series on HBM4.
- Part 1: Overview on the HBM standard
- Part 2: HBM implementation challenges
- Part 3: Custom HBM implementations