To GPU or not GPU
Over the past decade, GPUs became fundamental to the progress of artificial intelligence (AI) and machine learning (ML). They are widely used to handle large-scale computations required in AI model training and inference, and are playing an increasingly important role in data centers. The key feature of the GPU is its ability to perform parallel processing efficiently, making it ideal for training machine learning models, which require numerous computations to be carried out simultaneously.
However, as the demand for AI computing increases, the overall efficiency of this technology is being called into question. Industry data suggests that roughly 40% of time is spent in networking between compute chips across a variety of workloads, bottlenecked by limited communication capacity (fig. 1).
The demand for AI applications continues to rise and this connectivity issue comes at the same time as the costs of general-purpose GPUs for specific workloads and their high power consumption are motivating a move away from GPU-centric compute architectures, towards custom silicon and chiplet-based designs. These modular and flexible SoCs enable scalable hardware solutions that can be optimized not only to reduce power consumption, and cost but improve communication bandwidth too.
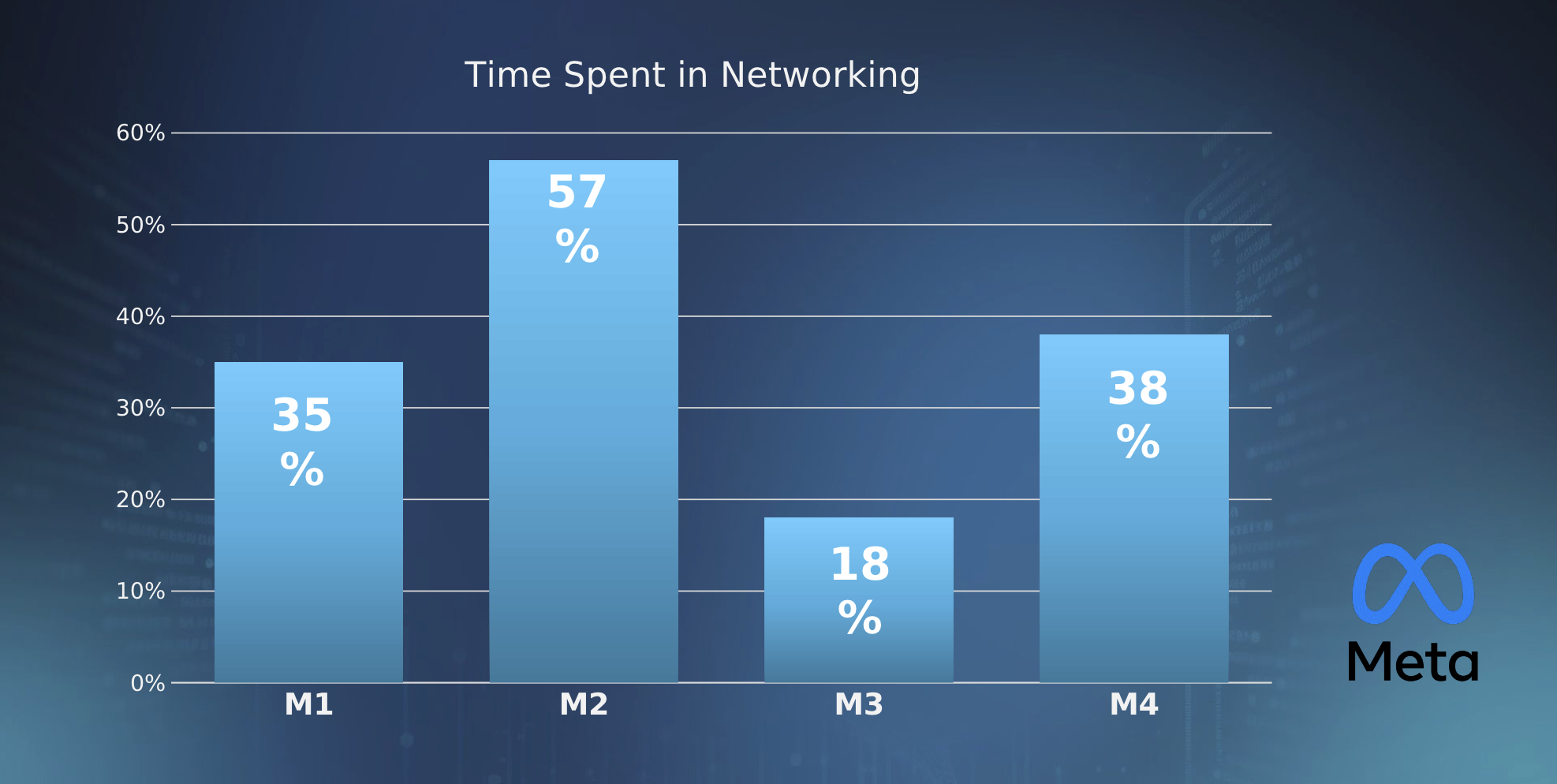
Figure 1: Case studies presented by Meta suggest that, for its models, approximately 40 percent of the time data resides in a data center is wasted in processor to processor transference.
Why GPUs are reaching their limits
GPUs are pivotal in advancing AI due to their parallel processing capabilities, which allow them to handle the intensive, simultaneous calculations required to meet the needs of AI training, such as processing enormous datasets and accelerating model training times. Certainly, GPUs have been extremely successful in this role.
However, GPUs are an expensive option, in terms of cost and energy. Their design focuses on 64-bit elements to handle a broad range of computational tasks, but in real-time AI workloads, dropping the 64-bit components could reduce die size and energy requirements by up to a third, while still meeting most AI processing needs.
Despite their efficiency in training scenarios, GPUs face significant downsides in scaling AI applications for widespread use. As AI moves towards real-time inference, particularly in edge environments where data must be processed close to its source, the high cost and power consumption associated with GPUs will become increasingly unsustainable.
Instead, AI-dedicated ASICs now offer a more cost-effective and powerful alternative for specific inference tasks and can often offer a faster performance and lower power consumption for those specific functions compared to GPUs.
Transition to inference-only models and edge AI
The industry's priorities are shifting from training to inference, emphasizing the need for scalable, energy-efficient hardware solutions suited for edge deployments. Edge AI devices, which process data on-site rather than transferring it to a central data center, benefit from lightweight, specialized chips that emphasize inference over training.
Arm-based architectures are steadily emerging as a strong alternative to GPUs, with architectures like Neoverse delivering high performance for AI inference at the edge with lower energy and cooling demands than would be needed in a GPU-based data center. Because of their low power consumption, Arm chips are already widely used in mobile devices and their architecture is being adapted for AI, particularly for edge computing scenarios where power efficiency is needed.
By focusing on inference-only models, these specialized chips can support AI workloads in constrained environments, making edge AI not only feasible, but also more efficient and adaptable. The transition to edge AI and inference-dedicated architectures could lessen reliance on traditional GPUs while broadening the AI computing landscape to include more diverse, task-optimized hardware solutions.
The scalability challenge and connectivity barriers
Scaling AI to meet mass-market demands introduces some serious challenges. Monolithic GPUs are currently constrained to 858 mm2, the maximum reticle size in photolithographic equipment. This not only limits how many transistors can be placed on a single chip, but also dictates a physical perimeter limit, which restricts the number of input/output (I/O) connections, and therefore directly impacts data bandwidth.
Furthermore, larger chips not only increase manufacturing costs, but also introduce defect risks and reduce yields.
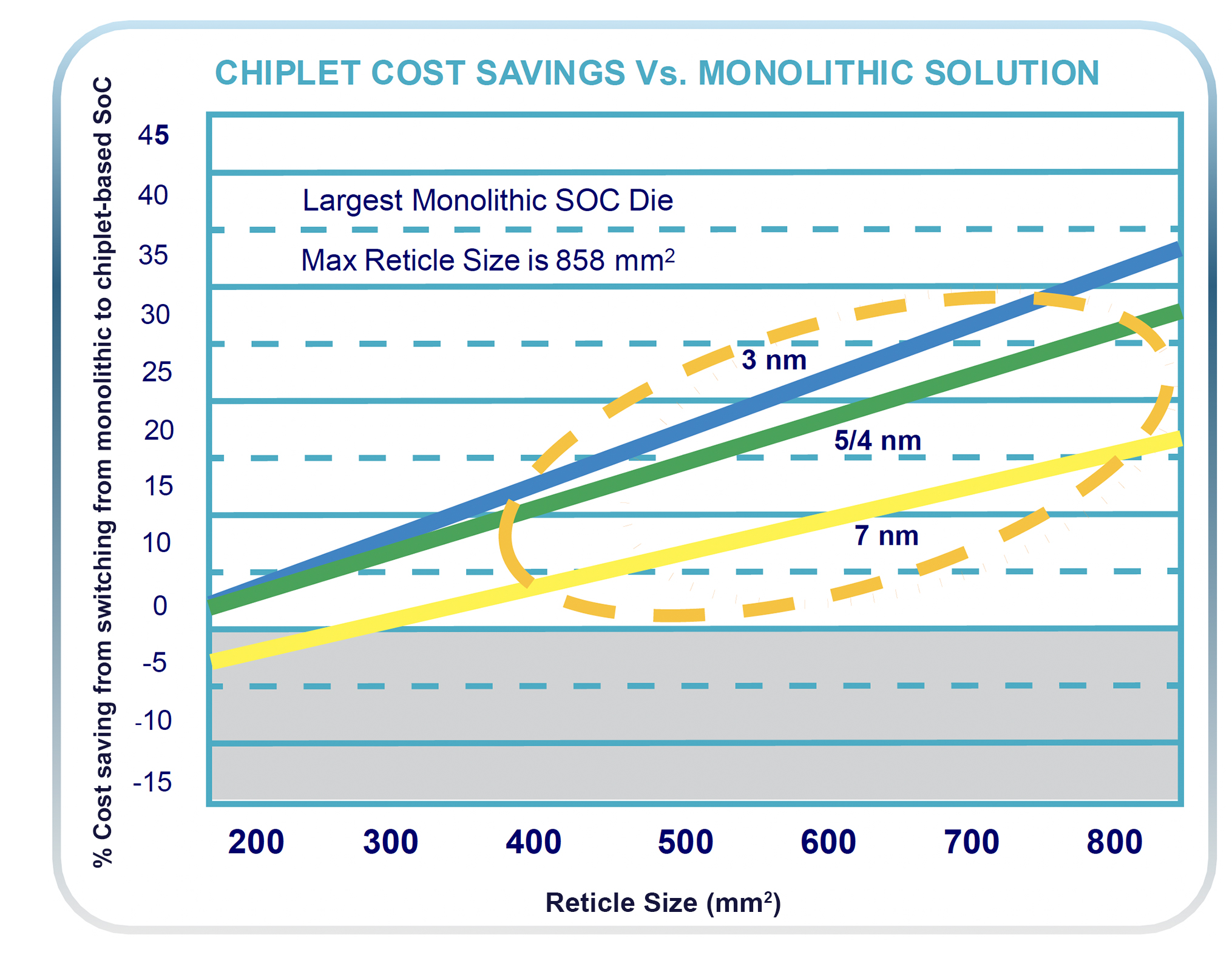
Figure 2: Moving to a chiplet design in 7, 5, and 3 nm can reduce the total cost of ownership – by more than 30 percent for the largest SoCs on advanced processes.
As AI workloads scale, their I/O connectivity bottlenecks become increasingly problematic. This wasted networking time is posing an increasingly significant barrier to AI, as real-time communication between nodes becomes critical for large-scale deployments. This scalability barrier, coupled with the reticle limitations of manufacturing equipment, highlights the need for an alternative design approach, with chiplet-based architectures better supporting AI applications at scale.
Breaking down barriers to scale with chiplets
Chiplets enable designers to optimize specific parts of the processor for AI workloads, such as matrix multiplications or memory management, enhancing performance while keeping costs down.
Unlike monolithic SoCs, chiplet-based designs offer a modular approach, breaking down the system into smaller, specialized units. Each chiplet can be optimized for a specific function – such as processing, memory management, or I/O operations – and can be developed using the optimal process for its function and cost, regardless of the process used in other parts of the chip. This means leading-edge processes (e.g. 5 nm, 3 nm or 20Å) can be used for logic components, while larger, cost-efficient processes can be used for analog components.
Chiplet architectures reduce the total cost of ownership for large SoCs by more than 30%, significantly lowering non-recurring engineering (NRE) costs and improving power efficiency.
Furthermore, by integrating chiplets from multiple vendors, companies can build more flexible and scalable AI hardware using only “best-of-breed” components and removing dependence on a single provider.
Chiplets also enable more effective data movement within the SoC, resolving the connectivity bottlenecks that challenge traditional architectures by reducing latency and enhancing communication bandwidth, both of which are essential for real-time AI inference.
Chiplets also remove the issue of reticle size constraints that limit the performance of monolithic SOCs, opening up greater I/O capacity without sacrificing yields or introducing manufacturing defects.
Companies like Alphawave Semi offer innovative custom silicon ASIC solutions for AI computing. These chiplet solutions can outperform general-purpose GPUs in certain tasks because they are designed to handle very specific workloads.
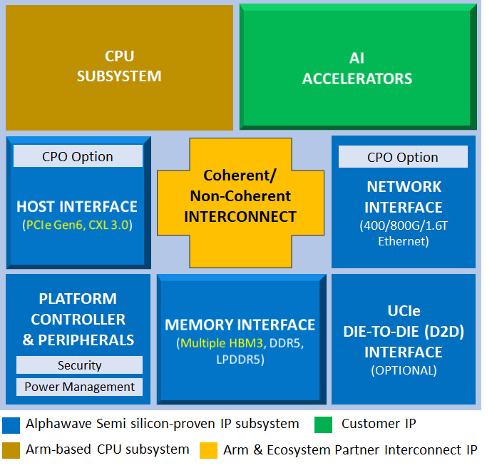
Figure 3: Alphawave Semi can overcome performance, power and space limitations through custom silicon ASICs designed to accelerate specialized AI applications, whether it is machine learning training or inference, generative AI or neural nets.
To GPU, or not to GPU, that is the question
NVIDIA’s dominance in the GPU market, which commands more than 90% of the data center market share, is built on a combination of powerful hardware and an extensive software ecosystem.
But the question is not ‘How can smaller GPU vendors compete against NVIDIA?’. It is ‘Is the GPU even needed as we move from training to inference models?’.
As we saw with Arm in the mobile sector, disruptive players can take over from well-established industry leaders. Dominance in one domain does not guarantee success in another, and in the mobile sector, Arm’s IP model enabled its technology to dominate the market through its adoption by companies such as Qualcomm.
Chiplets are effectively an evolution of the IP model, and in a similar way, Nvidia’s supremacy in AI hardware can be challenged by chiplet-based architectures, which distribute functionality across smaller, interconnected modules and offer the combined advantages of higher I/O density and better data throughput as well as lower costs and greater energy efficiency, especially when used in custom configurations tailored to specific workloads with a fast time-to-market.
As AI scales, the GPU model’s limitations in cost and power efficiency are becoming increasingly apparent. GPUs will continue to play a pivotal role in AI training, but a shift towards chiplets-based SoCs and AI-dedicated ASICs is already emerging.
Chiplets in particular stand out as a key enabler for future AI computing, reducing manufacturing costs, power usage, and network bottlenecks.
The debate over the post-GPU era of AI computing remains lively. To explore this topic in more detail, watch this panel discussion titled "To GPU or not GPU: Is that the question?", featuring Carl Freud from Cambrian-AI Research, Dr. John Summers from RISE Research Institutes of Sweden, and Tony Chan Carusone, CTO of Alphawave Semi. In this panel debate, they discuss the significance of GPUs in AI and the custom solutions that are most likely to challenge the status quo.